Core Models
At it’s core, Vapi is an orchestration layer over three modules: the transcriber, the model, and the voice.
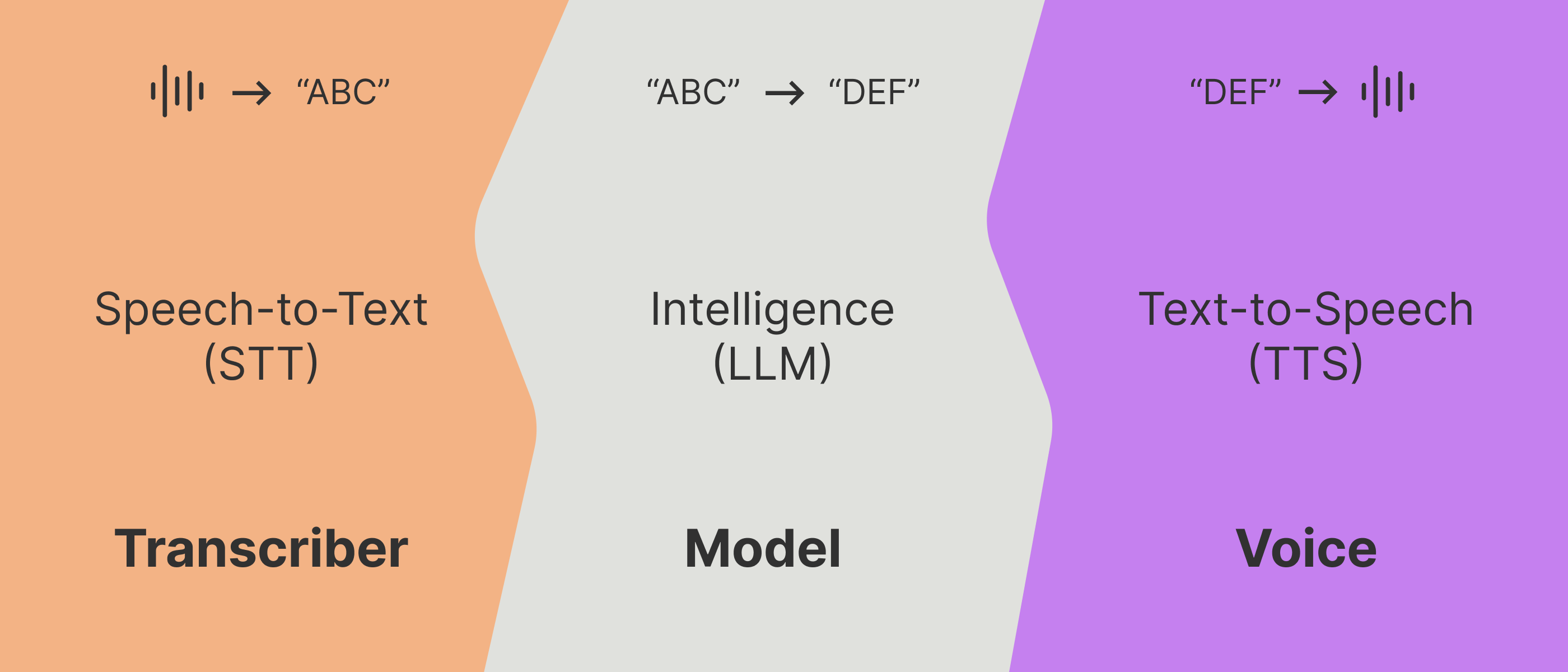
These three modules can be swapped out with any provider of your choosing; OpenAI, Groq, Deepgram, ElevenLabs, PlayHT, etc. You can even plug in your server to act as the LLM.
Vapi takes these three modules, optimizes the latency, manages the scaling & streaming, and orchestrates the conversation flow to make it sound human.
Listen (intake raw audio)
When a person speaks, the client device (whether it is a laptop, phone, etc) will record raw audio (1’s & 0’s at the core of it).
This raw audio will have to either be transcribed on the client device itself, or get shipped off to a server somewhere to turn into transcription text.
Run an LLM
That transcript text will then get fed into a prompt & run through an LLM (LLM inference). The LLM is the core intelligence that simulates a person behind-the-scenes.
Speak (text → raw audio)
The LLM outputs text that now must be spoken. That text is turned back into raw audio (again, 1’s & 0’s), that is playable back at the user’s device.
This process can also either happen on the user’s device itself, or on a server somewhere (then the raw speech audio be shipped back to the user).
Vapi pulls all these pieces together, ensuring a smooth & responsive conversation (in addition to providing you with a simple set of tools to manage these inner-workings).